Updating files in Amazon EFS - Part 2

The first part of this blog series discusses updating EFS placed in private subnet using AWS CodePipeline. This post discusses achieving the same using a lambda function as the heart of the solution.
Using Lambda function - High Level
- Have the files uploaded to a S3 bucket from the source/origin
- Create a lambda function in the vpc and configure it to mount the target EFS
- Configure a (cloudwatch) lambda trigger as S3 object upload into the S3 bucket created.
- Have the lambda function copy/sync the files from S3 to the EFS
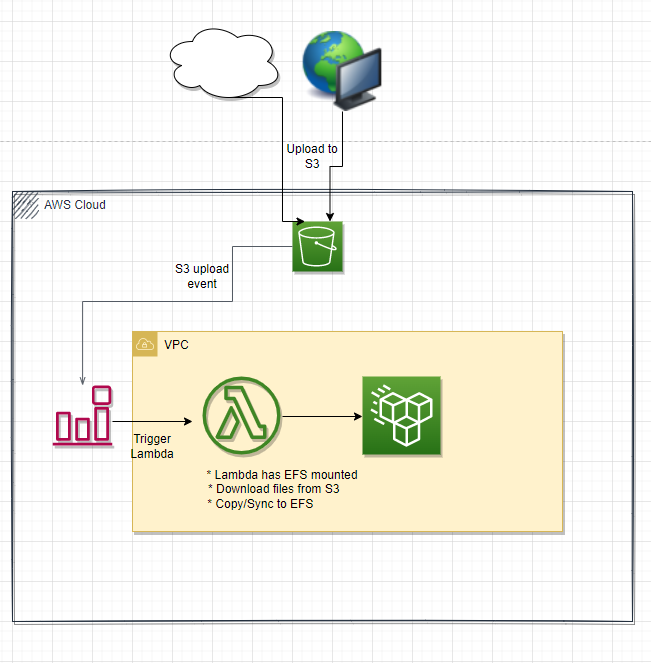
Pros:
- The S3 file upload doesn't need to be in zip format. Files can be individually uploaded as they are changed.
- Usually faster than the CodePipeline approach.
Cons:
- Copy files from S3 to a local directory in lambda may require some additional coding compared to a simple cli command execution (example: s3 cp s3://sources3/location /mnt/efs/location ) as in the case of codebuild. One may need to build/use a lambda layer that provides the AWS CLI functionality or have a few lines of code building the S3 to EFS functionality.
- Lambda can not run more than 15 minutes. So using lambda is not practical if the copy operation is going exceed 15 mins.
Configuring the lambda trigger can be tricky when there are too many files and folders involved. For example, one may have a folder textFiles with multiple .txt files, an image folder with various images of gif, jpeg etc. and another folder scripts with many .py, .sh, .js etc files. Configuring the trigger then becomes erroneous and may cause multiple lambda trigger for a single upload that involves multiple files. This could be worked around by
Having a special trigger object: Have a predefined file or a predefined folder (and have files with predefined format in it), then configure that as the trigger for the lambda function. For example, trigger/-startupdate.txt. This would allow us to configure the s3 trigger with prefix as trigger/ and suffix as -startupdate.txt. Downside of this approach is that from the file origin we should create an extra file with the pattern (-startupdate.txt in our example) and upload to S3.
Upload as zip: The other alternative is to upload the whole files as a zip so we only have a single file to configure the S3 trigger. The lambda will extract and copy/sync files to S3. Again, this option is limited by the available ephemeral storage and currently that is 10GB with the recent update
A sample implementation of the approach discussed above can be found in this github repository
The approach discussed here and in the previous part of the series are useful only when it is possible to push the files from their source to a S3 bucket. But there can be situations where the files are generated to a network fileshare/drive and the files need to be copied/synced to EFS. The next part in the series will discuss the options to sync files from network fileshare/drive to EFS.


