Updating files in Amazon EFS - Part 1

Amazon EFS is a widely used AWS service. Be it applications running in EC2 instances or containers or serverless apps, EFS provide the 'external file storage' or a 'shared file storage' capability. Since the same EFS can be mounted from different places, it can help different apps share files among them.
It is common for the files in EFS to have a different life cycle compared to the applications where they are consumed. The files may be produced or updated by a disconnected system or process which may or may not co-exist with the consumers running inside the AWS environment.
This series discusses a few options (DIY and AWS provided) to load and update the files in EFS, when
- The files in EFS is used by applications running in Fargate containers
- The EFS is placed in the private subnets of the VPC
- And the origin/source of the files are outside of the AWS account where EFS is located (on-premise/other cloud etc.)
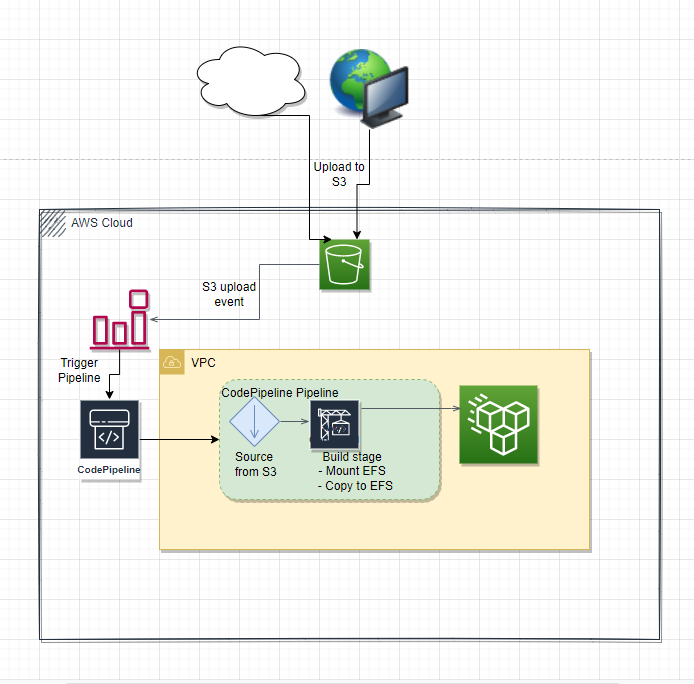
Scenario - From S3 buckets
This is the scenario where it is possible to copy/sync files to S3 buckets when they are generated/updated from their origin.
High Level
- Have the source system upload all the files to a S3 bucket as a zip file
- The zip file is used as the 'source' of an AWS CodePipeline
- The zip upload to S3 trigger the AWS code pipeline
- Next stage in the codepipeline is an AWS CodeBuild. Have the build agent spin up within the VPC and mount the target EFS to the build agent.
- Build commands copy/sync source files to the expected location/s.
Pros:
- This provides a nice and clean 'pipeline' for the file update
- AWS CodePipeline and CodeBuild UI provides an easy way to see the pipeline execution history
Cons:
- AWS CodePipeline expects the source object as a 'zip' file when S3 is used as the source. So from the origin of the files a zip file has to be constructed to upload to S3, even if it is for a single file change.
A minimal example of the above solution can be found in this github repository.
The next part of this series will discuss another solution to address the same scenario.


